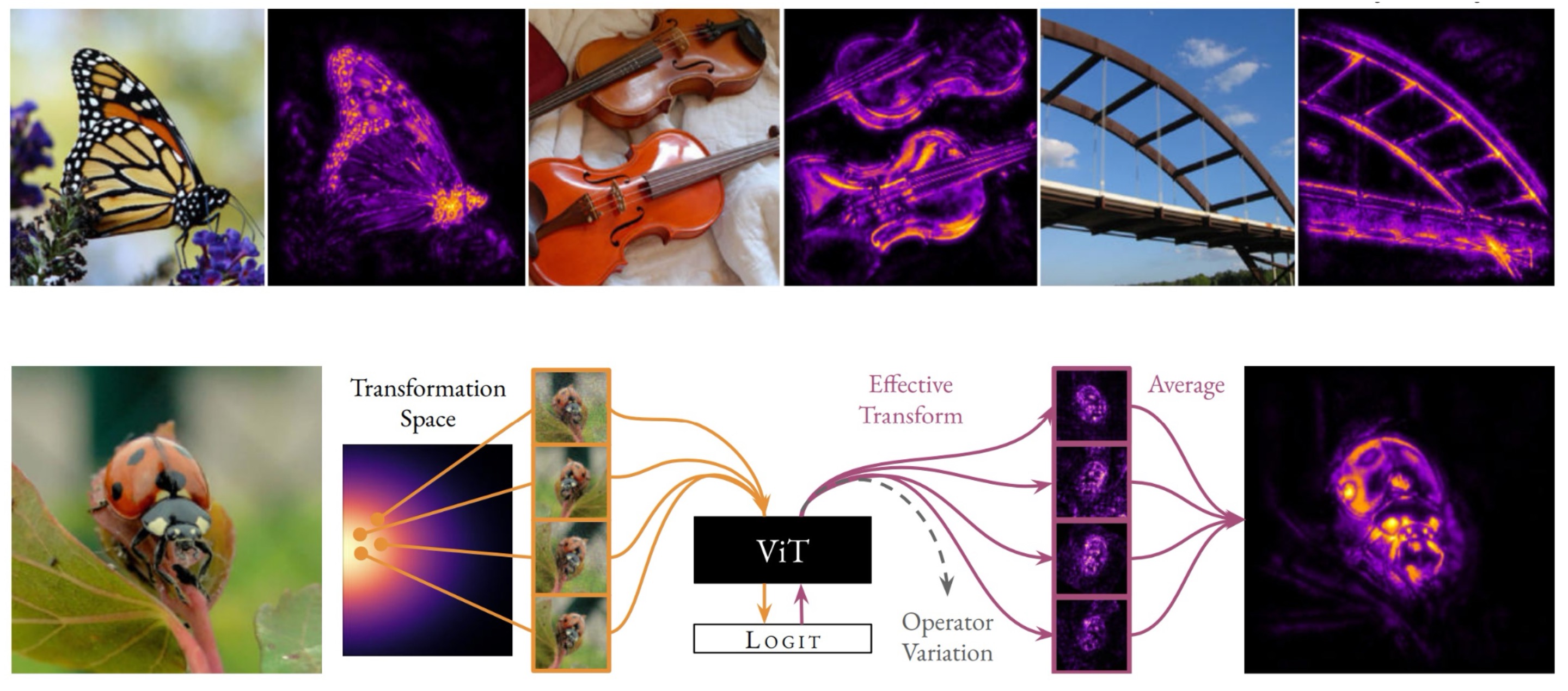
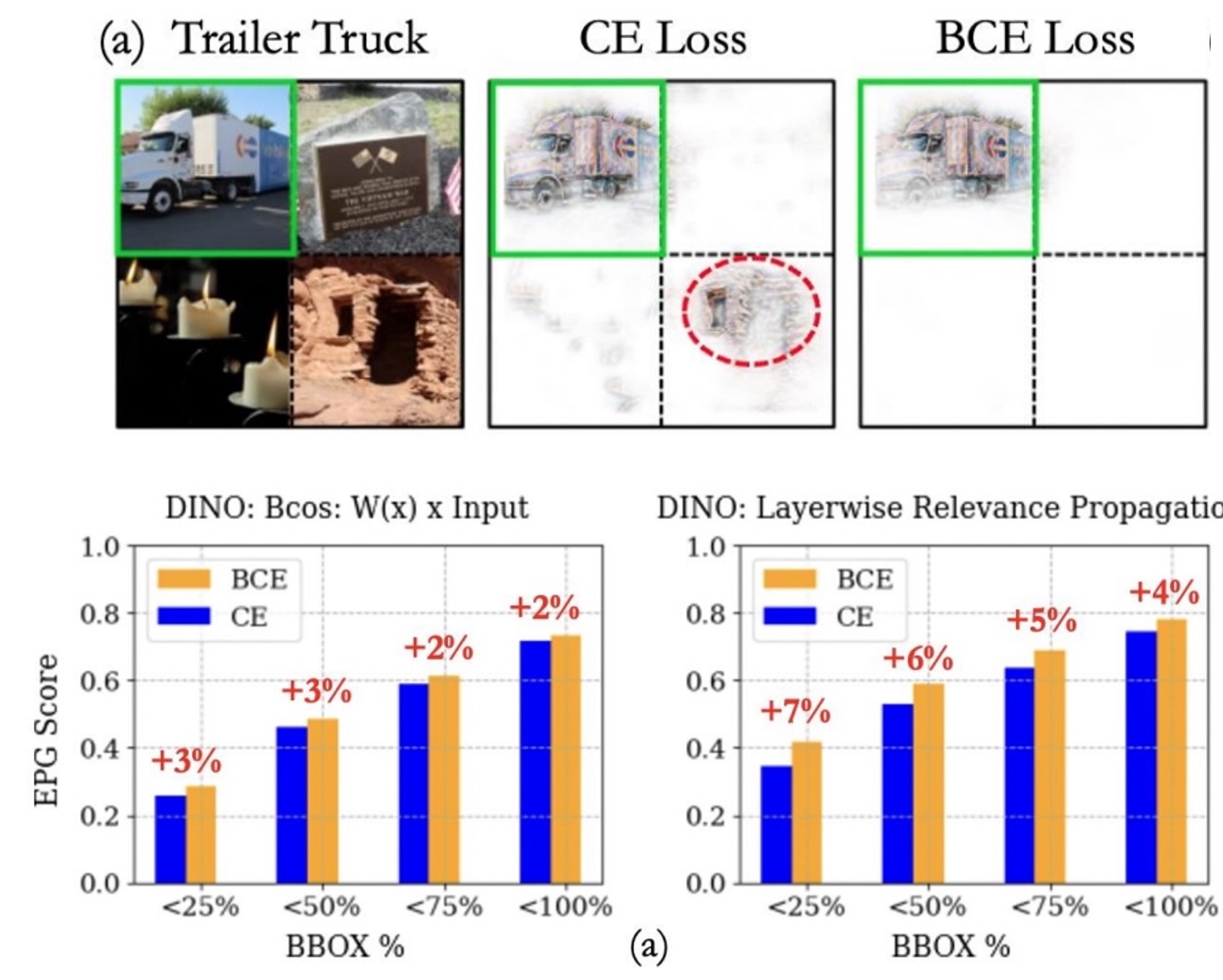
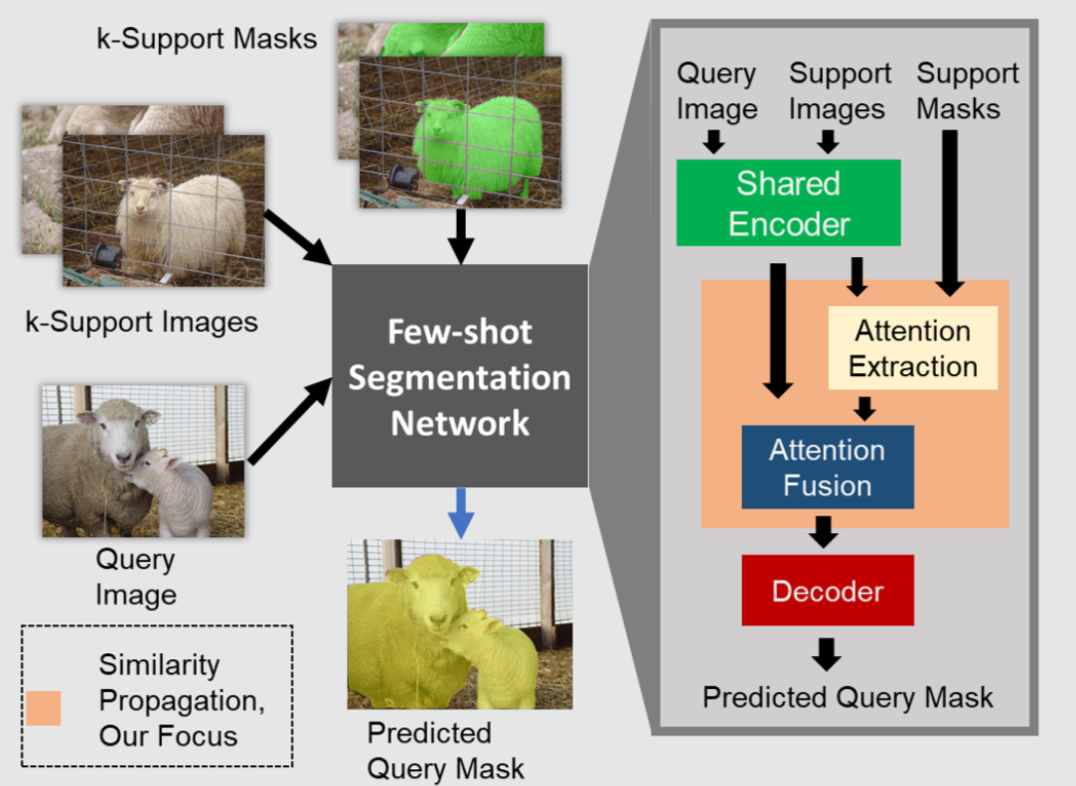
I am an ELLIS PhD Student advised by Prof. Bernt Schiele (Max Planck Institute of Informatics, Saarbrücken) and Prof. Francesco Locatello (ISTA). During the course of my PhD I shall be associated with both the Max Planck Institute for Informatics and Institute of Science and Technology, Austria.
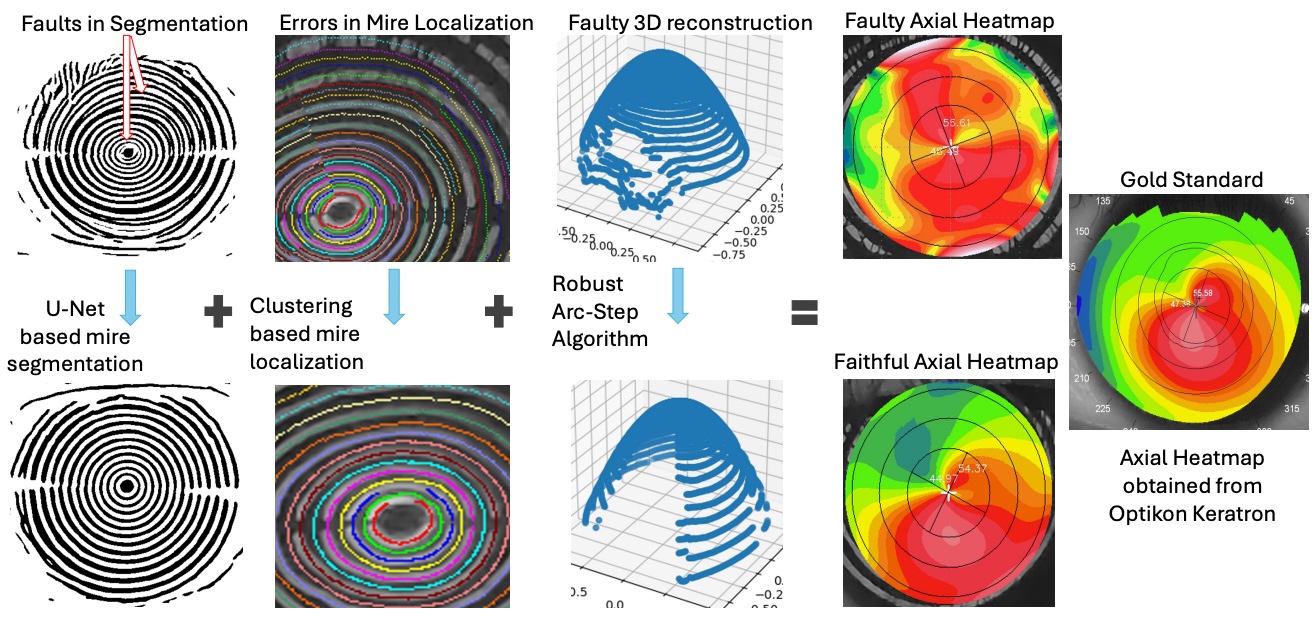
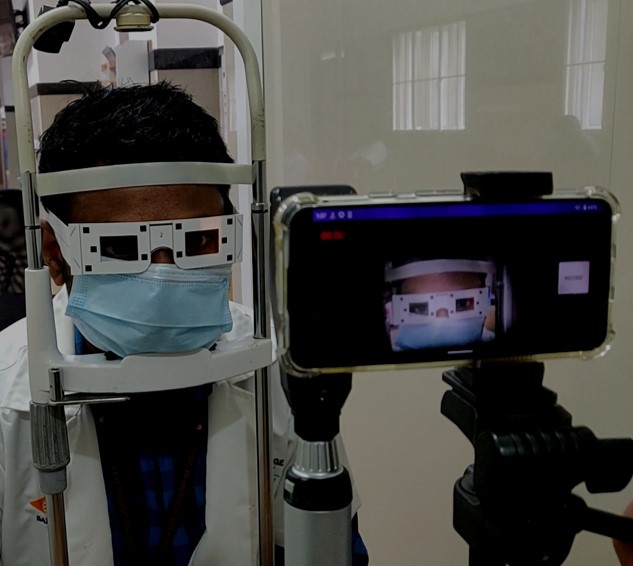
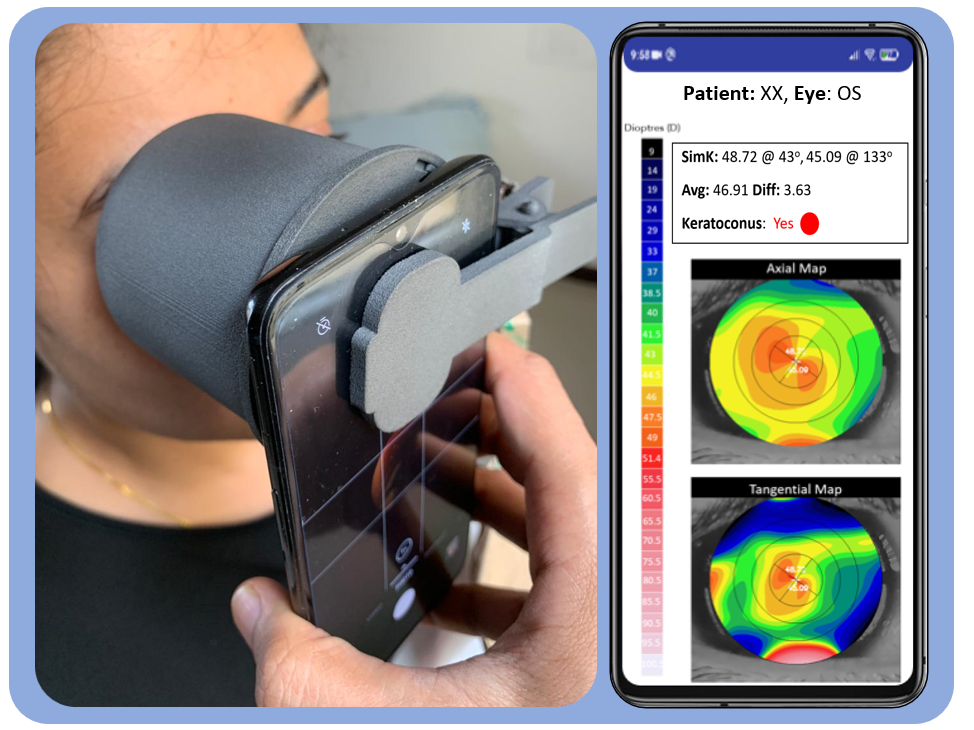
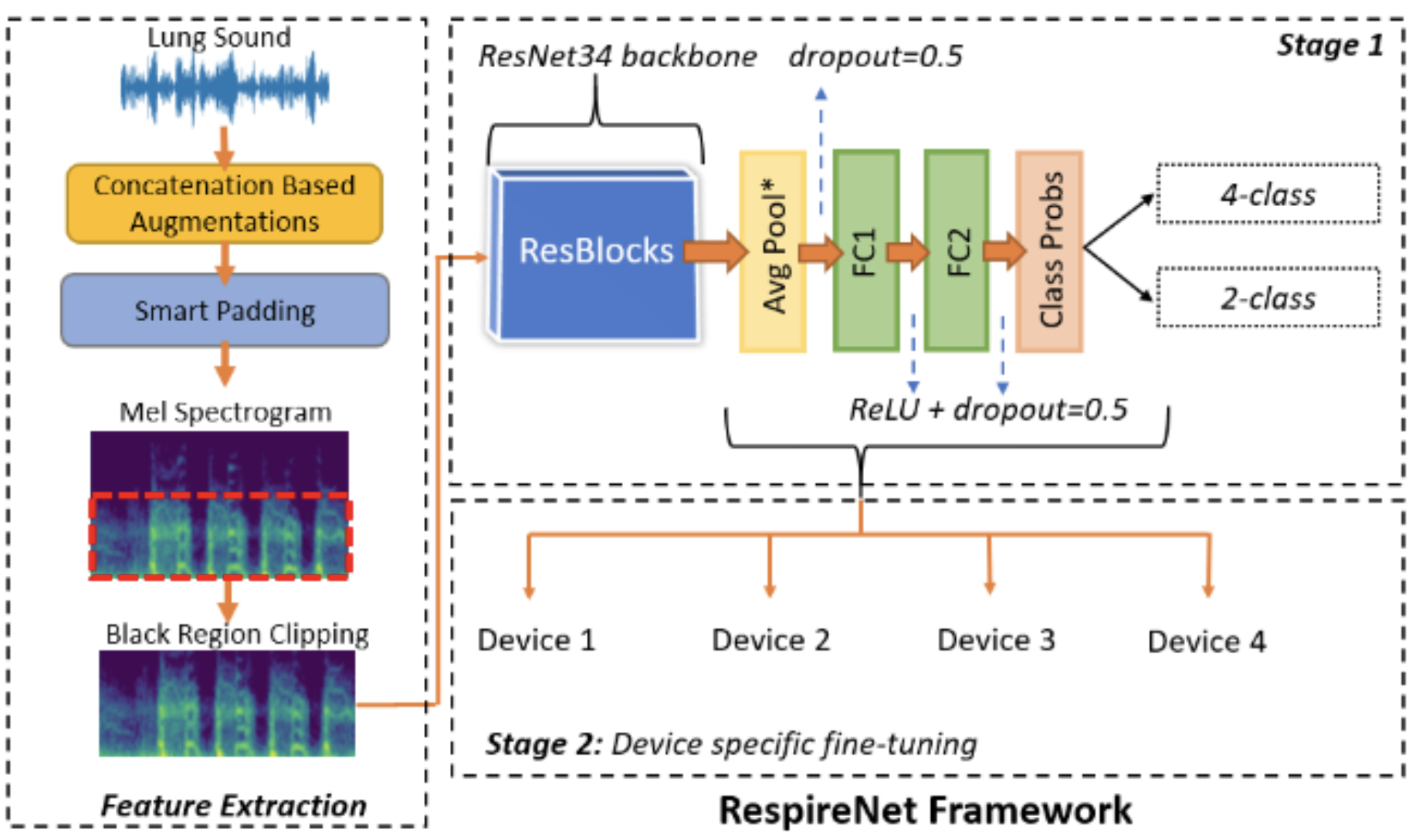
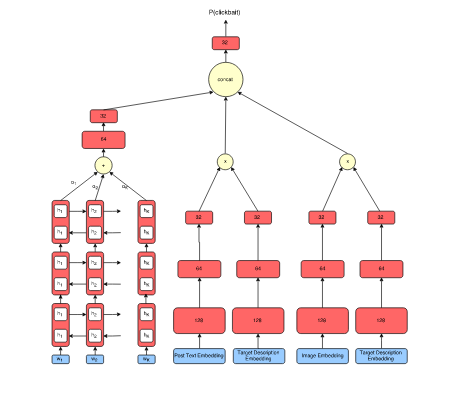
Previously, I was a Research Fellow at Microsoft Research (MSR), India in the Technology for Emerging Markets group, where I worked on applications of Computer Vision, Image Processing and Machine Learning to developing low-cost diagnostic solutions for healthcare. Before that, I worked as a Research Intern at Adobe Inc. in the Media and Data Science Research Group on image understanding tasks.
I completed my Master's and B.Tech with Honours in May, 2020 at IIIT Hyderabad, where I was advised by Prof. PJ Narayanan. My work was mainly on learning robust unsupervised style representations for image recognition and retrieval tasks.